The AI landscape changed forever when Meta released Llama 3 to the open source community. For the first time, developers gained access to large language models that genuinely compete with closed-source alternatives like GPT-4 and Claude—without subscription fees, usage restrictions, or vendor lock-in controlling your innovation.
This isn’t just another incremental update. Llama 3 represents a fundamental shift in how AI capabilities get distributed. Where previous open source models lagged significantly behind proprietary counterparts, Llama 3 closes that gap dramatically. The 70-billion parameter version outperforms models that cost thousands monthly to access, while the compact 8-billion parameter variant runs efficiently on consumer hardware that most developers already own.
Yet despite its transformative potential, confusion surrounds Llama 3’s actual capabilities, limitations, licensing terms, and practical implementation. Marketing materials tout impressive benchmarks, but what does that mean for real applications? Documentation explains technical architecture, but how do you actually deploy these models in production? Community forums debate performance, but which version suits your specific use case?
After extensively testing Llama 3 across dozens of real-world applications, analyzing its training methodology, implementing it in production environments, and tracking its rapid evolution through multiple releases, I’ve assembled this comprehensive guide answering every crucial question developers face when evaluating and implementing Meta’s open source AI models. Similar to how ChatGPT continues evolving with each iteration, Llama 3’s development demonstrates Meta’s commitment to advancing open source AI capabilities.
Understanding Llama 3: What It Actually Is
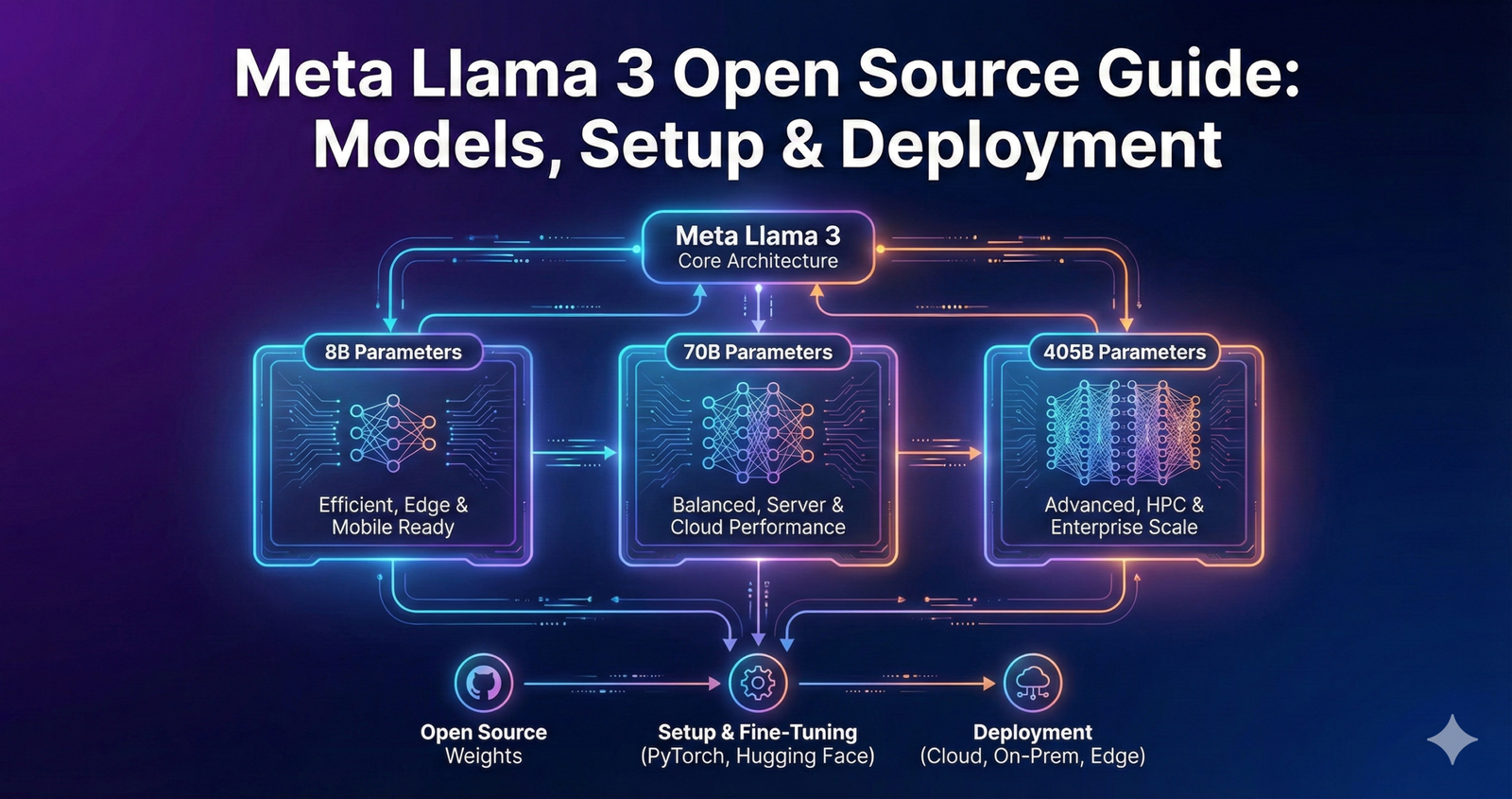
Meta Llama 3 is a family of open source large language models released in multiple sizes (8B, 70B, 405B parameters) optimized for text generation, conversation, coding, and reasoning tasks, available for both research and commercial use under Meta’s permissive license.
Before diving into technical details, understanding what Llama 3 fundamentally represents prevents unrealistic expectations and implementation mistakes.
Llama 3 constitutes a collection of foundation models—neural networks pretrained on massive text datasets that can be adapted for countless specific tasks. Unlike chatbot applications that provide fixed user experiences, Llama 3 models function as raw capabilities that developers integrate into their own applications, customize through fine-tuning, and deploy according to their unique requirements.
The “3” designation indicates this is Meta’s third major generation, following the original LLaMA (2023) and Llama 2 (2023). Each generation brought substantial improvements: better training data, architectural refinements, enhanced safety measures, and broader licensing permissions.
Meta initially released Llama 3 in April 2024 with 8-billion and 70-billion parameter versions. This marked a major leap over Llama 2, demonstrating performance that genuinely competed with GPT-3.5 and approached GPT-4 on many benchmarks. The community responded enthusiastically—downloads surged past 300 million within months.
In July 2024, Meta expanded the lineup with Llama 3.1, introducing the groundbreaking 405-billion parameter model—the first openly available AI that rivals frontier closed-source models. This release also expanded context windows to 128K tokens (roughly 100,000 words) and added support for eight languages beyond English.
September 2024 brought Llama 3.2, focusing on multimodal capabilities with vision models (11B and 90B parameters) that process both text and images, plus ultra-compact models (1B and 3B parameters) optimized for edge devices and mobile applications.
Most recently, December 2024’s Llama 3.3 70B surprised the community by delivering performance comparable to the massive 405B model while maintaining the efficiency and cost-effectiveness of the smaller 70B architecture. This represented a breakthrough in post-training optimization that challenged conventional wisdom about model scaling.
Each Llama 3 variant comes in two forms: base (pretrained) models suitable for fine-tuning to specific tasks, and instruct-tuned models optimized for conversational applications and following instructions. Most developers start with instruct-tuned versions unless they have specific fine-tuning plans.
The “open source” designation requires clarification. While Meta releases model weights, architecture details, and training information publicly, Llama 3 uses a custom license rather than traditional open source licenses like MIT or Apache 2.0. This license permits broad commercial use but includes specific restrictions we’ll explore in the licensing section.
The Complete Llama 3 Model Family: Which Version to Choose
The expanding Llama 3 ecosystem offers multiple models optimized for different use cases, hardware constraints, and performance requirements. Selecting the appropriate version significantly impacts both capability and deployment feasibility.
Llama 3 8B: Consumer-Friendly Powerhouse
The 8-billion parameter model democratizes AI by running efficiently on consumer-grade hardware while delivering impressive capabilities for its size.
Best suited for:
- Developers working on personal computers or modest cloud instances
- Applications requiring fast response times (chatbots, real-time assistants)
- Budget-conscious projects where cost per inference matters
- Learning and experimentation before scaling to larger models
- Edge deployment scenarios with hardware constraints
The 8B model requires approximately 16GB of RAM (with quantization), making it accessible on high-end consumer GPUs or even recent MacBooks with unified memory. Response times remain snappy, typically generating 20-50 tokens per second depending on hardware.
Performance-wise, Llama 3 8B significantly outperforms previous generation open source models of similar size. On standard benchmarks like MMLU (Massive Multitask Language Understanding), it achieves scores around 66-68%, approaching GPT-3.5 territory. For many practical applications—content creation, basic coding assistance, information extraction, conversational AI—this capability level proves entirely sufficient.
Limitations emerge when tasks require extensive world knowledge, complex multi-step reasoning, or handling highly specialized technical domains. The smaller parameter count constrains the model’s capacity to internalize vast information and perform sophisticated inference chains.
Llama 3 70B: Professional-Grade Performance
The 70-billion parameter model represents the sweet spot for serious production applications, balancing capability with reasonable resource requirements.
Best suited for:
- Production applications requiring high-quality outputs
- Complex reasoning and coding tasks
- Professional content generation (marketing, technical writing, analysis)
- Customer service applications handling nuanced queries
- Applications where response quality justifies higher computational costs
Llama 3 70B demands more substantial hardware—typically 140GB+ RAM or VRAM for full precision, though 4-bit quantization reduces this to roughly 35-40GB, making deployment feasible on high-end consumer GPUs or modest cloud instances with A100 or similar GPUs.
Performance reaches genuinely impressive levels. The model competes directly with GPT-4 on many tasks, sometimes exceeding it on specific benchmarks. MMLU scores hover around 82-86%, demonstrating strong general knowledge and reasoning capabilities. Coding performance on HumanEval approaches 88%, rivaling specialized code models.
This model excels at nuanced tasks requiring judgment, context awareness, and sophisticated reasoning. It handles complex instructions reliably, maintains coherent context across lengthy conversations, and generates outputs that often require minimal editing for professional use.
Llama 3.1 405B: Frontier-Level Capabilities
The massive 405-billion parameter model competes with the absolute best closed-source alternatives, representing Meta’s flagship achievement in open source AI.
Best suited for:
- Enterprise applications requiring maximum capability
- Synthetic data generation for training smaller models
- Complex research and analysis tasks
- Applications where output quality is paramount regardless of cost
- Model distillation (using 405B outputs to improve smaller models)
Resource requirements prove substantial—full deployment requires 810GB+ memory, practically mandating distributed deployment across multiple GPUs. Even with aggressive quantization, expect 200GB+ requirements. Cloud costs for hosting 405B make it economically viable primarily for high-value applications or batch processing rather than interactive use.
The performance justifies these requirements for demanding applications. Llama 3.1 405B achieves benchmark scores matching or exceeding GPT-4 and Claude across most standard evaluations. It demonstrates exceptional instruction following (92.1 on IFEval), strong mathematical reasoning (73.4 on MMLU PRO), and excellent coding abilities (89.0 on HumanEval).
For most developers, the 405B model serves specialized roles rather than everyday deployment. Common use cases include generating high-quality training data, creating evaluation datasets, serving as a “teacher” model for distillation, and handling occasional tasks where maximum capability matters more than cost efficiency.
Llama 3.3 70B: Efficiency Breakthrough
December 2024’s surprise release demonstrated that clever post-training techniques can extract frontier-level performance from more efficient architectures.
Best suited for:
- Applications previously considering 405B but deterred by costs
- Production deployments prioritizing cost-performance ratio
- Multilingual applications (supports 8 languages)
- Instruction-following tasks and tool use
- Coding assistance and technical applications
Llama 3.3 70B requires identical resources to standard Llama 3 70B (roughly 35-40GB with quantization) but delivers performance approaching the 405B model on many benchmarks. This represents exceptional value—achieving frontier capability at a fraction of the computational and financial cost.
Benchmark performance demonstrates the breakthrough: 86.0 on MMLU Chat, 88.4 on HumanEval for coding, 92.1 on IFEval for instruction following, and 91.1 on multilingual tasks. These scores match or exceed the previous-generation 70B while approaching 405B territory, all while costing just $0.10 per million input tokens and $0.40 per million output tokens on inference services—roughly 10-15 times cheaper than GPT-4o or Claude.
The secret lies in advanced post-training optimization techniques including improved supervised fine-tuning, enhanced reinforcement learning from human feedback, and sophisticated prompt engineering during training. Meta essentially extracted more capability from the same underlying architecture through better training methodologies rather than simply scaling parameters. This development challenges the “bigger is always better” assumption that dominated AI scaling discussions, similar to how Google Gemini demonstrated that architecture matters as much as raw parameter count.
Llama 3.2 Vision Models: Multimodal Capabilities
The 11B and 90B vision models extend Llama 3’s capabilities beyond text to understand and reason about images.
Best suited for:
- Visual question answering applications
- Document analysis and OCR-intensive tasks
- Image understanding and description
- Visual content moderation
- Combined text-and-image reasoning
These multimodal models process both text prompts and image inputs, enabling applications that understand visual context. The 11B variant offers efficiency for simpler visual tasks, while 90B provides more sophisticated image reasoning capabilities.
Use cases span document processing (extracting information from forms, receipts, diagrams), accessibility applications (describing images for visually impaired users), content moderation (detecting inappropriate visual content), e-commerce (analyzing product images), and educational tools (explaining diagrams and visual concepts).
Llama 3.2 Lightweight Models: Edge Deployment
The compact 1B and 3B models target on-device deployment scenarios where connectivity, privacy, or latency considerations prevent cloud-based inference.
Best suited for:
- Mobile applications requiring local AI
- Privacy-sensitive applications avoiding cloud transmission
- IoT devices with limited computational resources
- Offline-capable applications
- Real-time applications requiring minimal latency
These models run efficiently on smartphones, tablets, and embedded devices. While capabilities remain limited compared to larger variants, they enable entirely new application categories where cloud dependency proves impractical or unacceptable.
Example applications include on-device writing assistants, real-time translation without internet connectivity, privacy-preserving personal assistants, smart home devices with local processing, and augmented reality applications requiring instant response.
Technical Architecture: What Makes Llama 3 Different
Understanding Llama 3’s architectural innovations helps developers optimize implementation and anticipate capabilities.
Optimized Transformer Architecture
Llama 3 employs the transformer architecture that powers most modern language models, but with specific optimizations that improve efficiency and performance.
Grouped-Query Attention (GQA): Instead of the standard multi-head attention used in earlier models, Llama 3 implements GQA, which reduces memory requirements and speeds up inference while maintaining quality. This architectural choice particularly benefits larger models where memory bandwidth becomes a critical bottleneck.
GQA works by grouping multiple attention heads together and sharing key-value pairs across groups rather than maintaining separate copies for each head. This reduces the memory and computational cost of the attention mechanism—the most expensive component of transformer models—without significantly impacting output quality.
For developers, GQA means faster inference and lower memory requirements compared to models using traditional attention, directly translating to cost savings and better user experience in production deployments.
Enhanced Tokenizer
Llama 3 introduces a completely redesigned tokenizer with a vocabulary of 128,256 tokens—four times larger than Llama 2’s 32,000-token vocabulary.
This expansion brings multiple advantages:
- More efficient text encoding, requiring fewer tokens to represent the same content
- Better multilingual support, with improved representation of non-English languages
- Enhanced code handling, with programming languages tokenized more efficiently
- Improved performance on technical content containing specialized terminology
The larger vocabulary means prompts consume fewer tokens, reducing costs on token-based pricing models. It also improves the model’s ability to work with diverse content types without losing nuance through aggressive compression.
However, the new tokenizer introduces incompatibility with previous Llama generations. Fine-tuned Llama 2 models cannot directly transfer to Llama 3 without retraining or adaptation.
Massive Training Scale
Llama 3 models were pretrained on over 15 trillion tokens—seven times more data than Llama 2. This massive training scale directly contributes to the models’ enhanced capabilities and broad knowledge base.
The training data comes from publicly available sources, carefully curated and filtered to ensure quality. Meta employed multiple filtering stages:
- Heuristic filters removing low-quality or spam content
- NSFW filters eliminating inappropriate material
- Semantic deduplication preventing repetitive training data
- Text quality classifiers predicting content value
- Llama 2 itself serving as a classifier to identify high-quality training examples
This multi-stage curation process ensures the model trains on diverse, high-quality content spanning general knowledge, technical information, creative writing, code, and multilingual text.
Training occurred across massive GPU clusters—specifically, 24,000 NVIDIA H100 GPUs for the standard models, with the 405B model consuming 39.3 million GPU hours. For perspective, that represents over 4,400 years of continuous single-GPU computation compressed into months through distributed training.
Despite this astronomical computational investment, Meta achieved net-zero greenhouse gas emissions by powering training facilities with 100% renewable energy, demonstrating that frontier AI development can align with environmental responsibility.
Advanced Fine-Tuning Methodology
The instruct-tuned Llama 3 variants undergo sophisticated alignment training beyond basic supervised fine-tuning.
Supervised Fine-Tuning (SFT): The model learns from over 10 million human-annotated examples demonstrating desired conversational behaviors, instruction following, and helpful responses.
Rejection Sampling: During training, the model generates multiple candidate responses to prompts. Human evaluators or reward models identify the best responses, and the model learns to prefer high-quality outputs over lower-quality alternatives.
Proximal Policy Optimization (PPO): This reinforcement learning technique fine-tunes the model to maximize reward signals from human preferences while preventing drastic deviations from the base model that could destabilize performance.
Direct Preference Optimization (DPO): A more recent technique that directly optimizes the model to prefer human-preferred responses without requiring explicit reward modeling, simplifying the alignment process.
This multi-technique approach produces models that don’t just generate coherent text—they follow instructions accurately, maintain helpful and harmless conversation, refuse inappropriate requests, and provide responses aligned with human preferences for quality and safety.
Comprehensive Performance Benchmarks
Benchmark scores provide objective comparison points, though real-world performance depends heavily on specific use cases and implementation quality.
General Knowledge and Reasoning
MMLU (Massive Multitask Language Understanding) tests knowledge across 57 subjects including mathematics, history, science, and professional domains.
- Llama 3 8B: 66.7% (5-shot)
- Llama 3 70B: 82.0% (5-shot)
- Llama 3.1 405B: 88.6% (0-shot, CoT)
- Llama 3.3 70B: 86.0% (0-shot, CoT)
For context, GPT-4 achieves approximately 86-88% on this benchmark, while GPT-3.5 scores around 70%. The Llama 3 70B and above models demonstrate knowledge rivaling the best closed-source alternatives.
GPQA Diamond measures reasoning on graduate-level science questions.
- Llama 3 70B: 48.0%
- Llama 3.1 405B: 50.7%
- Llama 3.3 70B: 50.5%
These challenging questions test deep reasoning rather than memorized facts, revealing the models’ genuine analytical capabilities.
Mathematical and Symbolic Reasoning
MATH benchmark evaluates mathematical problem-solving across various difficulty levels.
- Llama 3 8B: 30.0% (4-shot)
- Llama 3 70B: 50.4% (4-shot)
- Llama 3.1 405B: 73.8% (0-shot, CoT)
- Llama 3.3 70B: 77.0% (0-shot, CoT)
The substantial improvement from 8B to 70B demonstrates how parameter count impacts complex reasoning tasks. The 405B and 3.3 70B models approach human expert performance on many mathematical challenges.
GSM-8K tests grade-school math word problems.
- Llama 3 8B: 79.6% (8-shot, CoT)
- Llama 3 70B: 93.0% (8-shot, CoT)
- Llama 3.1 405B: 96.8% (8-shot, CoT)
Even the smaller models handle basic mathematics reliably, while larger variants achieve near-perfect accuracy.
Coding Capabilities
HumanEval measures Python code generation from natural language descriptions.
- Llama 3 8B: 62.2% (0-shot)
- Llama 3 70B: 81.7% (0-shot)
- Llama 3.1 405B: 89.0% (0-shot)
- Llama 3.3 70B: 88.4% (0-shot)
These pass rates indicate the percentage of programming problems solved correctly on the first attempt—impressive performance rivaling specialized coding models.
MBPP (Mostly Basic Python Problems) tests broader programming capabilities.
- Llama 3 8B: 72.8% (3-shot)
- Llama 3 70B: 82.5% (3-shot)
- Llama 3.1 405B: 88.6% (3-shot)
- Llama 3.3 70B: 87.6% (base)
Llama 3 models demonstrate strong coding abilities across the family, making them viable alternatives to specialized code generation tools for many applications.
Multilingual Performance
MGSM (Multilingual Grade School Math) evaluates multilingual reasoning.
- Llama 3 70B: 68.9% (0-shot)
- Llama 3.1 405B: 91.6% (0-shot)
- Llama 3.3 70B: 91.1% (0-shot)
Llama 3.1 and 3.3 models support eight languages: English, German, French, Italian, Portuguese, Hindi, Spanish, and Thai. Performance remains strong across languages, though English typically achieves slightly higher scores.
Instruction Following
IFEval measures how accurately models follow specific constraints and instructions.
- Llama 3.1 405B: 88.6%
- Llama 3.3 70B: 92.1%
This benchmark tests whether models respect detailed requirements like word count limits, format specifications, tone requirements, and structural constraints—critical for production applications where precise instruction adherence matters.
Practical Implementation: Getting Started with Llama 3
Moving from interest to implementation requires understanding download, setup, and deployment workflows.
Accessing Model Weights
Meta distributes Llama 3 through multiple channels, each suited to different use cases and technical preferences.
Official Meta Website: Visit llama.com and submit an access request. After accepting the license agreement, you’ll receive a signed download URL via email within minutes to hours. This URL grants access to official model weights in Meta’s native format.
The download script (download.sh) requires wget and md5sum utilities. Running the script with your signed URL initiates downloads of model weights, tokenizer, and configuration files. Remember that download links expire after 24 hours and a certain number of downloads—you can request new links if expiration occurs.
Model weights are substantial: the 8B model weighs about 16GB, 70B approximately 140GB, and 405B around 800GB. Plan downloads accordingly, ensuring sufficient bandwidth and storage.
Hugging Face Hub: For developers already integrated with the Hugging Face ecosystem, model weights are available directly through the platform. Simply visit the model card (e.g., meta-llama/Meta-Llama-3-8B-Instruct) and follow download instructions.
Hugging Face provides both transformers-compatible weights and native Llama format. The transformers integration enables immediate use with familiar APIs:
python
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Meta-Llama-3-8B-Instruct")
model = AutoModelForCausalLM.from_pretrained("meta-llama/Meta-Llama-3-8B-Instruct")This approach simplifies deployment for developers comfortable with Hugging Face tools.
Cloud Platform Integration: Major cloud providers offer Llama 3 through their AI platforms:
- AWS through SageMaker and Bedrock
- Google Cloud through Vertex AI
- Microsoft Azure through Azure AI
- Databricks, Snowflake, and other data platforms
Cloud deployment eliminates weight downloads and hardware management, providing API access with automatic scaling. This approach suits production applications requiring reliability and minimal operational overhead.
Hardware Requirements
Understanding resource needs prevents deployment surprises and informs infrastructure planning.
Llama 3 8B:
- Full precision (FP16): ~16GB VRAM/RAM
- 8-bit quantization: ~8GB VRAM/RAM
- 4-bit quantization: ~4-6GB VRAM/RAM
Consumer GPUs like NVIDIA RTX 4090 (24GB), RTX 4080 (16GB), or even RTX 3090 (24GB) handle 8B models comfortably. Apple Silicon Macs with 16GB+ unified memory run quantized versions efficiently.
Llama 3 70B:
- Full precision (FP16): ~140GB VRAM/RAM
- 8-bit quantization: ~70GB VRAM/RAM
- 4-bit quantization: ~35-40GB VRAM/RAM
Deployment typically requires professional GPUs like NVIDIA A100 (40GB or 80GB), H100 (80GB), or distributed deployment across multiple consumer GPUs. Cloud instances with appropriate GPU configurations cost $1-3 per hour depending on provider and region.
Llama 3.1 405B:
- Full precision (FP16): ~810GB VRAM/RAM
- 8-bit quantization: ~405GB VRAM/RAM
- 4-bit quantization: ~200-250GB VRAM/RAM
Even aggressive quantization requires distributed deployment across multiple high-end GPUs. Practical deployment almost always occurs via cloud providers with multi-GPU infrastructure rather than self-hosted hardware.
Inference Frameworks and Tools
Multiple frameworks facilitate Llama 3 deployment, each with distinct advantages.
- Transformers (Hugging Face): The most accessible option for developers familiar with Python and ML tooling. Provides simple APIs, extensive documentation, and broad community support. Best for prototyping, research, and applications prioritizing ease of development over maximum performance.
- vLLM: Optimized inference server achieving significantly faster throughput than naive implementations. Uses PagedAttention and continuous batching to maximize GPU utilization. Ideal for production deployments serving multiple concurrent requests where performance matters.
- llama.cpp: CPU-focused implementation enabling deployment on systems without GPUs. Includes Metal acceleration for Apple Silicon Macs. Perfect for local development, edge deployment, or scenarios where GPU access proves impractical.
- TensorRT-LLM: NVIDIA’s optimized inference library delivering maximum performance on NVIDIA GPUs through advanced optimization techniques. Best for performance-critical production deployments on NVIDIA hardware.
- Ollama: User-friendly tool for running LLMs locally with simple command-line interface. Handles model download, quantization, and serving automatically. Excellent for developers wanting quick local deployment without infrastructure complexity.
Each framework involves trade-offs between ease of use, performance, hardware compatibility, and feature sets. Most developers start with Transformers or Ollama for experimentation, then migrate to vLLM or TensorRT-LLM for production deployments requiring maximum efficiency.
Fine-Tuning for Specific Tasks
While pretrained models perform well out-of-box, fine-tuning adapts them to specific domains, writing styles, or task requirements.
When to Fine-Tune:
- Your application requires specialized knowledge not well-represented in general training
- You need consistent adherence to specific formats, tones, or style guidelines
- Domain-specific terminology or jargon appears frequently
- Output quality from base models proves insufficient for your standards
- You have sufficient high-quality training data (thousands of examples minimum)
Fine-Tuning Approaches:
- Full Fine-Tuning updates all model parameters using your custom dataset. This produces maximum adaptation but requires substantial computational resources—nearly as much as pretraining. Practical only for well-funded projects with access to multi-GPU infrastructure.
- Parameter-Efficient Fine-Tuning (PEFT) updates only a small fraction of parameters while freezing the majority. Techniques like LoRA (Low-Rank Adaptation) achieve 90%+ of full fine-tuning benefits while reducing computational requirements by 10-100x. Most developers should default to PEFT approaches.
- Instruction Fine-Tuning specifically teaches the model to follow instructions in your domain. Effective for creating specialized assistants or tools that need to understand domain-specific commands.
The Hugging Face ecosystem provides excellent tooling for fine-tuning through libraries like TRL (Transformer Reinforcement Learning), PEFT, and Accelerate. These abstractions hide much of the complexity while still allowing advanced customization when needed.
Fine-tuning requires careful data preparation—garbage in, garbage out applies forcefully to model training. Invest time creating high-quality examples that demonstrate exactly the behaviors you want the model to learn. Even a few hundred excellent examples often outperform thousands of mediocre ones.
Licensing and Commercial Use
Understanding Llama 3’s license prevents legal issues and clarifies what you can and cannot do commercially.
Core License Terms
Llama 3 uses Meta’s custom license rather than traditional open source licenses like MIT, Apache, or GPL. This “community license” permits broad use but includes specific conditions.
Permitted Uses:
- Commercial applications and services
- Research and academic use
- Fine-tuning and creating derivative models
- Redistribution of original or modified weights
- Integration into products and services
The license deliberately enables commercial use without royalties or usage fees—a significant advantage over closed-source alternatives charging per-token or subscription fees.
Required Attribution:
Derivative models must include “Llama 3” at the beginning of their name. Services and applications must display “Built with Meta Llama 3” attribution. This requirement ensures Meta receives credit while allowing developers freedom to build and monetize applications.
Monthly Active User Restriction:
If your product or service exceeds 700 million monthly active users, you must request an additional license from Meta. This clause primarily affects the largest tech companies; the vast majority of developers never approach this threshold.
For perspective, 700 million MAU places you among the top 20 internet services globally—larger than Twitter, Reddit, Netflix, or most major platforms. Startups, mid-sized companies, and even successful large businesses operate comfortably within this limit.
Prohibited Uses:
The license prohibits using Llama 3 to train other large language models without permission. This prevents competitors from simply using Llama as free training data for commercial rival models.
Additionally, the Acceptable Use Policy prohibits illegal activities, generation of harmful content, impersonation, spam, malware generation, and other misuses. These restrictions align with responsible AI practices most developers already follow.
Comparison to Closed-Source Licensing
Understanding how Llama 3’s license compares to proprietary alternatives highlights its advantages.
Cost Structure:
- Llama 3: Zero licensing fees, pay only for compute/infrastructure
- GPT-4: $10-60 per million tokens (input and output combined)
- Claude: $15-75 per million tokens depending on model tier
- Gemini: $1.25-7 per million tokens
For high-volume applications, Llama 3’s zero licensing cost creates dramatic savings. A chatbot serving 10 million conversations monthly might cost $50,000+ on proprietary APIs but only infrastructure costs (perhaps $5,000-15,000) with self-hosted Llama 3.
Control and Customization:
- Llama 3: Full control over deployment, fine-tuning, system prompts, and model modifications
- Proprietary models: Limited to provider-defined APIs and configurations
Applications requiring specific behaviors, integration with proprietary systems, or operation in restricted environments (air-gapped networks, on-premise deployment) benefit enormously from Llama 3’s flexibility.
Privacy and Data Governance:
- Llama 3: User data never leaves your infrastructure
- Proprietary models: All prompts and responses transmitted to third-party servers
For applications handling sensitive data—healthcare records, financial information, proprietary business data—self-hosted Llama 3 eliminates third-party data exposure risks entirely. This makes it viable for industries with strict regulatory requirements.
Vendor Independence:
- Llama 3: No dependency on provider uptime, pricing changes, or service continuity
- Proprietary models: Subject to provider rate limits, price increases, deprecation, or service changes
Building mission-critical applications on proprietary APIs introduces business risks. API providers change pricing, deprecate models, modify capabilities, or experience outages beyond your control. Llama 3 eliminates these vendor dependencies. Much like how businesses evaluate Microsoft Copilot for integration flexibility, Llama 3’s open nature provides strategic advantages for long-term product development.
Production Deployment Strategies
Moving Llama 3 from experimentation to production requires addressing scalability, reliability, cost optimization, and operational concerns.
Inference Serving Options
Self-Hosted Deployment:
Running Llama 3 on your own infrastructure provides maximum control and potentially lowest long-term costs for high-volume applications.
Advantages:
- Complete data privacy and control
- No per-token costs beyond infrastructure
- Full customization of serving logic
- Independence from third-party services
- Predictable costs that scale linearly with usage
Challenges:
- Requires ML/DevOps expertise
- Infrastructure management overhead
- Upfront capital or cloud commit for GPUs
- Responsibility for uptime and scaling
- Security and maintenance burden
Self-hosting makes sense for organizations with existing ML infrastructure, high query volumes justifying fixed costs, strict data privacy requirements, or technical teams capable of managing deployment complexity.
Managed Inference Services:
Numerous providers offer Llama 3 as a managed API, handling infrastructure while you pay per usage.
Major providers include:
- Together AI: $0.20-0.90 per million tokens
- Anyscale: $0.15-1.00 per million tokens
- Replicate: $0.65-4.00 per million tokens
- Groq: $0.05-0.69 per million tokens (extremely fast inference)
- Fireworks AI: $0.20-0.90 per million tokens
Managed services suit applications with variable workloads, teams lacking ML infrastructure expertise, projects requiring rapid deployment, or situations where operational simplicity outweighs cost optimization.
Hybrid Approaches:
Many organizations combine approaches based on workload characteristics:
- Self-host for predictable, high-volume workloads
- Use managed services for overflow capacity or experimental features
- Deploy critical paths self-hosted while outsourcing auxiliary functions
This hybrid strategy balances cost efficiency, operational simplicity, and risk management.
Performance Optimization
Maximizing inference efficiency directly impacts both user experience and operational costs.
Quantization:
Reducing numerical precision from 16-bit to 8-bit or 4-bit dramatically decreases memory requirements and increases throughput with minimal quality impact.
4-bit quantization typically maintains 95-98% of full-precision quality while reducing memory by 75% and increasing inference speed by 2-4x. This makes the difference between needing expensive 80GB GPUs versus affordable 24GB consumer GPUs for 70B deployment.
Tools like bitsandbytes, GPTQ, and AWQ provide production-ready quantization with simple APIs. Most applications should default to quantized deployment unless quality testing reveals unacceptable degradation.
Batching and Caching:
Processing multiple requests simultaneously amortizes model loading overhead across queries. Continuous batching techniques used by vLLM and TensorRT-LLM achieve 10-30x higher throughput compared to naive sequential processing.
KV-cache optimization stores intermediate computation results, preventing redundant calculations when processing related queries or continuing conversations. This dramatically accelerates multi-turn dialogues and follow-up questions.
Flash Attention:
Advanced attention implementations like FlashAttention-2 reduce memory consumption and accelerate processing of the attention mechanism—the computational bottleneck in transformer models. Integration is typically automatic in modern frameworks but worth verifying for performance-critical deployments.
Model Compilation:
PyTorch 2.0’s torch.compile() and similar optimization techniques compile models to optimized formats that execute faster than standard eager execution. Compilation overhead occurs once at startup but delivers 20-40% speedups for subsequent inference.
Monitoring and Observability
Production systems require comprehensive monitoring to maintain reliability and optimize performance.
Key Metrics to Track:
Inference Latency: Time from request receipt to response completion. Track p50, p95, and p99 percentiles to identify slowest requests affecting user experience.
Throughput: Requests processed per second or tokens generated per second. Helps capacity planning and identifies performance degradation.
GPU Utilization: Percentage of GPU compute and memory actively used. Low utilization suggests inefficient batching or configuration; sustained high utilization indicates scaling needs.
Cost Per Request: Total infrastructure cost divided by request volume. Tracks whether optimizations successfully reduce operational expenses.
Error Rates: Frequency of failed requests, out-of-memory errors, timeout failures, and other issues requiring investigation.
Output Quality Metrics: Application-specific measures of response helpfulness, accuracy, or appropriateness. May involve automated scoring, user feedback, or manual sampling.
Tools like Prometheus, Grafana, DataDog, and New Relic integrate well with ML inference infrastructure, providing dashboards and alerting for production monitoring.
Cost Optimization Strategies
Llama 3’s open nature enables aggressive cost optimization unavailable with proprietary APIs.
Right-Size Your Model:
The 8B model costs roughly 10x less to serve than 70B for comparable workloads. Many applications achieve acceptable quality with smaller models, especially after fine-tuning to specific domains.
Run quality evaluations across model sizes using your actual use cases. Deploy the smallest model meeting quality requirements rather than defaulting to the largest available.
Optimize Inference Configuration:
Reducing maximum token generation limits prevents unnecessary computation on lengthy outputs. If your application needs only 200-token responses, configure hard limits preventing 2000-token generations.
Temperature, top-p, and other sampling parameters affect both quality and generation speed. Lower temperature (more deterministic) often generates faster by reducing sampling overhead.
Leverage Spot Instances:
Cloud providers offer GPU instances at 50-90% discounts when you accept potential interruption. For batch processing or workloads tolerating occasional restarts, spot instances dramatically reduce costs.
Architectures using multiple smaller GPUs instead of single large GPUs enable spot instance use while maintaining availability—if one instance terminates, others continue serving traffic.
Cache Common Queries:
Many applications receive repetitive or similar questions. Caching generated responses for common inputs eliminates redundant computation. A simple Redis cache layer can reduce inference volume by 30-60% for chatbots or customer service applications.
Semantic caching matches queries by meaning rather than exact text, expanding cache hit rates. Tools like GPTCache provide production-ready semantic caching implementations.
Schedule Batch Workloads:
Non-time-sensitive processing (data analysis, content generation, summarization of archives) can run during off-peak hours when compute costs or GPU availability improve. Batch processing also enables higher GPU utilization through larger batch sizes.
Real-World Applications and Use Cases
Understanding how organizations successfully deploy Llama 3 provides practical insights and implementation patterns.
Customer Service and Support
Companies replacing expensive API calls with self-hosted Llama 3 chatbots report 60-80% cost reductions while maintaining or improving response quality.
A mid-sized e-commerce company deployed Llama 3 70B fine-tuned on their product catalog, return policies, and historical support tickets. The system handles 70% of incoming queries without human intervention, reducing average response time from 4 hours to under 1 minute while cutting support costs by $180,000 annually.
The fine-tuning process used 15,000 high-quality question-answer pairs from their best support agents. Parameter-efficient techniques enabled training on a single A100 GPU in approximately 8 hours, costing under $100 in cloud compute.
Content Generation and Marketing
Marketing agencies use Llama 3 for drafting blog posts, social media content, product descriptions, and advertising copy at scale.
One agency reports generating first drafts 10x faster than human writers alone, then using human editors for refinement and brand voice consistency. Their workflow:
- Brief creation defining topic, audience, tone, and key points
- Llama 3 70B generates 3-5 draft variations using custom system prompts
- Human editors select best draft and refine for brand consistency
- Final review ensures accuracy and adds unique insights
This hybrid approach increased content output from 20 to 150 pieces monthly while maintaining quality standards. The agency estimates Llama 3 saves 200+ hours of writing time monthly while costing only $400-600 in inference costs.
Code Generation and Developer Tools
Software teams integrate Llama 3 into development workflows for code completion, documentation generation, test creation, and code review assistance.
A startup built an internal coding assistant using Llama 3 70B fine-tuned on their codebase, coding standards, and internal libraries. The tool:
- Suggests code completions based on project context
- Generates boilerplate code from natural language descriptions
- Creates unit tests from function implementations
- Explains complex code sections for onboarding
- Identifies potential bugs or security issues
Developer productivity metrics showed 25-35% faster completion of routine tasks, with junior developers benefiting most from contextual assistance. The self-hosted deployment ensures proprietary code never leaves company infrastructure—critical for security-conscious organizations.
Data Analysis and Business Intelligence
Enterprises use Llama 3 to democratize data access by translating natural language questions into SQL queries, interpreting analysis results, and generating reports.
A financial services firm deployed Llama 3.1 405B for complex analytical reasoning over their data warehouse. Non-technical business users ask questions like “Which customer segments showed declining retention in Q4?” and receive both SQL queries and plain-English explanations of findings.
The system reduces time from question to insight from days (waiting for analyst availability) to minutes (immediate self-service). Data teams shifted from executing routine queries to focusing on complex strategic analysis.
Education and E-Learning
Educational institutions leverage Llama 3 for personalized tutoring, assignment grading, content adaptation, and accessibility features.
An online learning platform fine-tuned Llama 3 70B on educational content across mathematics, science, and humanities. The AI tutor:
- Answers student questions with explanations tailored to their grade level
- Generates practice problems matching curriculum standards
- Provides step-by-step solutions highlighting key concepts
- Adapts explanations based on student comprehension signals
Student engagement increased 40% with AI tutoring availability, while learning outcomes improved measurably. The platform estimates one AI instance serves as many concurrent students as 100 human tutors at a fraction of the cost.
Healthcare and Medical Applications
Healthcare organizations deploy Llama 3 for clinical documentation, literature review, patient education, and administrative automation—always with appropriate human oversight.
A hospital system uses Llama 3 70B to generate clinical documentation drafts from physician voice notes. The workflow:
- Physician dictates patient encounter into mobile app
- Speech-to-text transcribes audio
- Llama 3 structures transcription into proper clinical note format
- Physician reviews and approves/edits documentation
This reduces documentation time from 2+ hours daily to 20-30 minutes, allowing physicians to see more patients or spend more time on complex cases. The self-hosted deployment ensures HIPAA compliance without third-party data transmission.
Important note: All healthcare applications require human review and approval. AI assists but never makes autonomous medical decisions.
Research and Scientific Computing
Research institutions use Llama 3 for literature review, hypothesis generation, experimental design, and scientific writing assistance.
A biotechnology research lab deployed Llama 3.1 405B to analyze thousands of research papers, identify patterns across studies, and suggest experimental approaches for drug development. The system:
- Summarizes relevant papers based on research questions
- Identifies contradictory findings requiring investigation
- Suggests experimental protocols based on successful precedents
- Generates grant proposal drafts from research summaries
Researchers report saving 15-20 hours weekly on literature review while discovering connections across disciplines they might otherwise miss. The comprehensive knowledge from 405B’s massive parameter count proves valuable for connecting disparate scientific domains.
Comparing Llama 3 to Competing Open Source Models
Understanding Llama 3’s position relative to alternatives helps inform model selection decisions.
Llama 3 vs. Mistral Models
Mistral AI offers strong open source alternatives, particularly the Mixtral 8x7B and Mixtral 8x22B mixture-of-experts models.
Advantages of Mistral:
- More efficient inference through sparse activation (MoE architecture)
- Strong multilingual capabilities
- Excellent performance-per-parameter ratio
- Active parameter counts smaller than total, reducing computational cost
Advantages of Llama 3:
- Larger model family with more size options (1B to 405B)
- Better ecosystem support and tooling maturity
- More extensive documentation and community resources
- Vision models for multimodal applications
For European language applications or scenarios prioritizing inference efficiency, Mistral models deserve serious consideration. For broader ecosystem support, proven scalability, and maximum capability, Llama 3 typically edges ahead.
Llama 3 vs. Falcon Models
Technology Innovation Institute’s Falcon models provide another open source alternative, particularly Falcon-180B.
Advantages of Falcon:
- Trained on high-quality, carefully curated RefinedWeb dataset
- Strong performance on reasoning benchmarks
- Permissive Apache 2.0 licensing
Advantages of Llama 3:
- Better instruction-following capabilities
- More active development and updates
- Larger community and ecosystem
- Superior multilingual support
Falcon represents solid technology but has seen less community adoption and slower development compared to Llama 3’s momentum. Most developers default to Llama unless specific Falcon advantages (particularly licensing) prove compelling.
Llama 3 vs. Yi Models
01.AI’s Yi models, particularly Yi-34B, offer competitive capabilities from a Chinese technology company.
Advantages of Yi:
- Excellent Chinese language performance
- Strong coding capabilities
- Commercial-friendly license
Advantages of Llama 3:
- Broader Western ecosystem integration
- More extensive English-language documentation
- Larger model family with more deployment options
- Better-known organization with Meta’s backing
For applications prioritizing Chinese language support, Yi deserves evaluation. For primarily English or Western European language applications, Llama 3’s ecosystem advantages typically outweigh Yi’s benefits.
Llama 3 vs. Command R+ (Cohere)
Cohere recently open-sourced Command R and Command R+, optimized for retrieval-augmented generation (RAG) applications.
Advantages of Command R+:
- Specifically optimized for RAG workflows
- Excellent citation and attribution capabilities
- Strong multilingual support (10 languages)
- Efficient context utilization
Advantages of Llama 3:
- Larger model options for maximum capability
- Broader general-purpose applications beyond RAG
- More mature ecosystem and tooling
- Vision capabilities in 3.2 family
For RAG-specific applications requiring strong citation handling, Command R+ competes effectively. For general-purpose applications or scenarios requiring largest possible models, Llama 3 maintains advantages. Similar to how developers compare <a href=”https://aicreativeblog.com/elon-musk-grok-ai-latest-news-updates/”>Grok AI’s unique approaches</a> to established alternatives, each open source model brings distinct strengths to different use cases.
Future Roadmap and Upcoming Developments
Meta continues actively developing the Llama ecosystem. Understanding the roadmap helps plan long-term implementations.
Confirmed Upcoming Features
Llama 4 Development:
Meta confirmed Llama 4 development is underway, with training utilizing over 100,000 NVIDIA H100 GPUs—more than 4x the compute scale used for Llama 3. Expected capabilities include:
- Significantly improved reasoning and mathematical abilities
- Enhanced multimodal understanding (text, images, audio, video)
- Better instruction following and agentic capabilities
- Longer context windows (possibly 256K+ tokens)
- Improved efficiency through architectural innovations
No official release date exists, but industry observers expect mid-to-late 2025 based on typical development timelines and Meta’s previous release cadence.
Extended Context Windows:
Current 128K token context (approximately 100,000 words) already handles most applications, but research continues on extending limits further. Future models may support 256K or even 1M+ token contexts, enabling analysis of entire books, codebases, or datasets in single prompts.
Improved Multimodal Capabilities:
Llama 3.2 vision models represent first steps toward comprehensive multimodal AI. Future versions will likely:
- Add native audio understanding for speech, music, and sound
- Support video input for temporal reasoning
- Enable multi-image reasoning across collections
- Generate multimodal outputs (text-to-image, text-to-audio)
Enhanced Safety and Alignment:
Ongoing research focuses on:
- More robust refusal of harmful requests without false positives
- Better handling of ambiguous or edge-case queries
- Improved factuality and reduced hallucinations
- Enhanced interpretability of model reasoning
Tool Use and Agentic Capabilities:
Future models will better leverage external tools, APIs, and systems:
- More reliable function calling and API integration
- Multi-step planning and execution
- Self-correction when errors occur
- Better understanding of when to use tools versus internal knowledge
Community Developments
The open source ecosystem surrounding Llama continually produces innovations Meta doesn’t directly control but that benefit all users.
Quantization Advances:
Community researchers develop increasingly aggressive quantization techniques maintaining quality at lower precision. Methods achieving acceptable performance at 3-bit or even 2-bit precision would democratize access to larger models on consumer hardware.
Efficient Fine-Tuning:
Techniques like QLoRA, IA3, and Adapter-based methods continue evolving, reducing the compute and data requirements for effective domain adaptation. Future methods may enable high-quality fine-tuning on single consumer GPUs for even the largest models.
Specialized Domain Models:
Community members create domain-specific Llama variants:
- Medical Llama models fine-tuned on clinical literature
- Legal Llama variants trained on case law and legal documents
- Finance-focused models incorporating market data and analysis
- Code-specialized variants optimizing programming performance
These specialized models outperform general-purpose variants in narrow domains while sharing the base Llama architecture and tooling.
Novel Applications:
Creative developers continually discover unexpected applications:
- Real-time language translation systems
- Interactive fiction and gaming AI
- Accessibility tools for disabled users
- Scientific discovery assistants
- Creative collaboration tools for artists and writers
The open nature of Llama enables experimentation that closed systems constrain through terms of service or API limitations.
Common Challenges and Solutions
Despite Llama 3’s capabilities, developers encounter predictable challenges during implementation. Understanding solutions accelerates successful deployment.
Challenge: Hallucinations and Factual Accuracy
Problem: Like all large language models, Llama generates plausible-sounding but factually incorrect information, especially on obscure topics or recent events beyond training data.
Solutions:
Retrieval-Augmented Generation (RAG): Combine Llama with vector databases containing verified information. When users ask questions, retrieve relevant factual content and include it in the prompt, grounding responses in actual data rather than parametric knowledge alone.
Citation Requirements: Instruct the model to cite sources when making factual claims. While it can’t access real sources without RAG, requiring citations reduces unfounded assertions.
Confidence Scoring: Ask the model to indicate confidence levels on factual statements. Low-confidence responses trigger additional verification or human review.
Fact-Checking Layers: Implement secondary verification using search APIs, knowledge graphs, or specialized fact-checking models to validate critical claims before presenting to users.
Domain Fine-Tuning: Training on curated, factual datasets in your specific domain improves accuracy for domain-specific applications while maintaining general capabilities.
Challenge: Inconsistent Instruction Following
Problem: Models sometimes ignore specific constraints, fail to follow format requirements, or misinterpret complex instructions.
Solutions:
Structured Prompting: Use consistent prompt templates with clear sections (Context, Instruction, Constraints, Format). Explicit structure helps models understand requirements.
Few-Shot Examples: Include 2-5 examples demonstrating desired behavior. Concrete examples clarify expectations better than abstract instructions.
Chain-of-Thought Prompting: For complex tasks, instruct the model to think step-by-step before responding. This improves adherence to multi-part instructions.
Iterative Refinement: If initial outputs miss requirements, provide feedback and request corrections rather than regenerating from scratch. Models often successfully adjust given specific correction guidance.
Fine-Tuning on Instructions: If your application requires consistent adherence to specific instruction patterns, fine-tune on examples demonstrating perfect instruction following in your domain.
Challenge: Context Window Management
Problem: Even with 128K token contexts, some applications (analyzing entire books, processing large codebases, long conversations) exceed limits.
Solutions:
Intelligent Chunking: Break long documents into semantic chunks that fit within context windows. Process chunks separately, then synthesize results.
Summarization Cascades: Summarize long inputs progressively—summarize chapters individually, then summarize the summaries for overall understanding.
Contextual Compression: Use specialized models or techniques to compress conversation history, retaining critical information while discarding redundant details.
External Memory Systems: Implement vector databases or knowledge graphs storing information referenced across long interactions, querying relevant context dynamically rather than maintaining everything in-context.
Sliding Windows: For sequential processing, maintain a moving context window containing recent information while archiving earlier content for potential retrieval if needed.
Challenge: Slow Inference Speed
Problem: Large models generate text slowly, creating poor user experience in interactive applications.
Solutions:
Aggressive Quantization: 4-bit quantization typically doubles or triples throughput with minimal quality impact for most applications.
Speculative Decoding: Advanced technique where a small, fast model generates candidate tokens that a larger model verifies. Achieves 2-3x speedups when candidates are mostly correct.
Streaming Responses: Display tokens as generated rather than waiting for complete responses. Users perceive faster interaction even if total generation time remains constant.
Model Distillation: Train smaller, faster models to mimic larger models’ behavior. Accept minor quality reductions for significant speed improvements.
Optimized Infrastructure: Use vLLM, TensorRT-LLM, or other optimized serving frameworks instead of naive implementations. Can achieve 5-10x improvements through better GPU utilization.
Caching: Cache responses to common queries. Many applications see 30-50% query repetition, allowing instant responses for cached content.
Challenge: Cost at Scale
Problem: Even without per-token licensing fees, infrastructure costs for high-volume applications become substantial.
Solutions:
Dynamic Model Selection: Route simple queries to 8B models and complex queries to 70B models. Saves 80-90% of computational cost while maintaining quality where it matters.
Batch Processing: For non-real-time workloads, accumulate requests and process in large batches during off-peak hours when compute costs less.
Autoscaling: Implement infrastructure that scales up during peak usage and down during quiet periods, paying only for needed capacity.
Spot Instances: Use interruptible cloud instances at 50-90% discounts for fault-tolerant workloads.
Edge Deployment: For appropriate use cases, deploy smaller Llama models (1B, 3B) directly on user devices, eliminating server costs entirely.
Prompt Optimization: Reduce unnecessary prompt verbosity. Shorter prompts process faster and cost less without sacrificing quality if well-crafted.
Getting Help and Community Resources
The Llama ecosystem includes extensive resources for developers seeking assistance, examples, and best practices.
Official Resources
Meta AI Website (llama.com): Official documentation, model downloads, licensing information, and announcements of new releases.
Hugging Face Model Cards: Comprehensive technical specifications, usage examples, benchmark scores, and download options for all Llama variants.
GitHub Repositories: Official Meta repositories contain reference implementations, evaluation code, and example applications demonstrating best practices.
Research Papers: Meta publishes detailed papers explaining Llama architecture, training methodology, safety measures, and benchmark evaluations. These provide deepest technical understanding for advanced users.
Community Resources
Hugging Face Forums: Active community discusses implementation challenges, shares fine-tuning techniques, and collaborates on domain-specific adaptations.
Reddit (/r/LocalLLaMA): Enthusiast community focused on running LLMs locally. Excellent resource for hardware recommendations, quantization techniques, and troubleshooting deployment issues.
Discord Servers: Multiple active communities (Hugging Face Discord, LocalLLaMA Discord, etc.) provide real-time assistance and discussion.
GitHub Discussions: Many popular Llama-related projects maintain active discussion forums where developers share solutions and request features.
YouTube Tutorials: Numerous creators produce video guides covering deployment, fine-tuning, application development, and advanced techniques.
Commercial Support
Several companies offer professional support, consulting, and managed services for organizations deploying Llama at scale:
- Hugging Face: Enterprise support, custom model development, infrastructure consulting
- Databricks: Integrated MLOps platform with Llama support and professional services
- Together AI: Managed inference with enterprise SLAs and deployment assistance
- AWS, Google Cloud, Azure: Cloud provider support teams assist with deployment on their respective platforms
Commercial support makes sense for organizations lacking internal ML expertise or requiring guaranteed response times for production issues.
Security and Safety Considerations
Deploying AI systems responsibly requires addressing security vulnerabilities and safety concerns proactively.
Prompt Injection and Jailbreaking
Risk: Malicious users craft inputs designed to manipulate model behavior, extract sensitive information, or bypass safety guardrails.
Mitigations:
- Validate and sanitize user inputs before passing to models
- Implement separate instruction and data channels (system prompts vs user messages)
- Monitor outputs for unexpected patterns suggesting successful manipulation
- Rate-limit requests from individual users to prevent systematic attack attempts
- Use additional filtering layers on outputs before displaying to users
Data Privacy and Leakage
Risk: Models might inadvertently expose training data, user information, or confidential system details through generated responses.
Mitigations:
- Never include sensitive information in prompts unless necessary
- Implement data access controls limiting what information models can reference
- Scrub or anonymize data before fine-tuning
- Audit model outputs for sensitive data leakage
- Use self-hosted deployments for sensitive applications to prevent third-party data exposure
Model Robustness and Reliability
Risk: Models produce incorrect, inappropriate, or harmful outputs despite safety training.
Mitigations:
- Implement human-in-the-loop review for high-stakes decisions
- Use confidence scoring to flag uncertain responses for review
- Maintain clear disclaimers about AI-generated content limitations
- Implement content filtering on outputs using specialized moderation models
- Regularly test models with adversarial inputs to identify vulnerabilities
Ethical Considerations
Best Practices:
- Disclose AI involvement to users interacting with Llama-powered systems
- Maintain human oversight for consequential decisions (medical, legal, financial)
- Monitor for biased outputs and implement mitigation strategies
- Provide feedback mechanisms allowing users to report inappropriate responses
- Consider societal impacts of your application beyond immediate technical functionality
Responsible AI deployment balances innovation with ethical considerations, ensuring technology benefits users without causing harm.
7 Frequently Asked Questions About Meta Llama 3
Q1: Is Meta Llama 3 truly free to use commercially?
Yes, Llama 3 is free for commercial use under Meta’s Community License, with no per-token fees or subscription costs. You pay only for infrastructure (compute, storage, bandwidth) needed to run the models. The only significant restriction is the 700 million monthly active user threshold—if your service exceeds this, you must request an additional license from Meta. This threshold is so high that it only affects the largest tech platforms globally. The vast majority of businesses, from startups to large enterprises, operate comfortably under this limit. Unlike proprietary APIs charging $10-75 per million tokens, Llama 3 enables unlimited generation once you’ve covered infrastructure costs, creating dramatic savings for high-volume applications.
Q2: Which Llama 3 model should I use for my application?
Choose based on your quality requirements, budget, and hardware constraints. For most production applications requiring high quality, Llama 3.3 70B offers the best balance—it delivers near-405B performance at 70B efficiency and cost. Use 8B for applications where fast response times matter more than maximum quality, budget constraints are tight, or deployment occurs on consumer hardware. Reserve 405B for applications where absolute maximum capability justifies the computational cost, such as generating training data, performing complex analysis, or serving as a quality benchmark. For vision tasks, use Llama 3.2 11B or 90B depending on complexity. Start with the smallest model meeting your quality threshold, then scale up only if testing reveals inadequacy.
Q3: How does Llama 3 compare to ChatGPT and Claude?
Llama 3.3 70B and 3.1 405B compete favorably with GPT-4 and Claude Sonnet/Opus on most benchmarks, sometimes matching or exceeding them on specific tasks. The key differences lie in deployment model rather than capability: proprietary models offer convenient APIs without infrastructure management but charge per-token and limit customization, while Llama requires self-hosting but provides unlimited generation, complete customization, and data privacy. For applications requiring specific behavior, handling sensitive data, or operating at high volume, Llama’s advantages typically outweigh API convenience. For low-volume experimentation or applications benefiting from provider-managed infrastructure, APIs may prove simpler despite higher per-use costs. Many organizations use both—APIs for prototyping and auxiliary functions, Llama for production workloads.
Q4: Can I fine-tune Llama 3 on my own data?
Yes, Llama 3’s license explicitly permits fine-tuning, and the open architecture makes it technically straightforward with modern tools. Parameter-efficient methods like LoRA enable fine-tuning even the 70B model on a single high-end consumer GPU (RTX 4090, A6000) or modest cloud instances. You’ll need quality training data—typically thousands of examples demonstrating desired behaviors—and some familiarity with Python and ML frameworks. Libraries like Hugging Face TRL, Axolotl, and Unsloth simplify the process significantly compared to training from scratch. Fine-tuning typically costs $50-500 depending on model size and data volume, far less than equivalent API costs for comparable customization. However, fine-tuning requires ML expertise; teams without this knowledge might start with prompt engineering and commercial fine-tuning services before building internal capabilities.
Q5: What hardware do I need to run Llama 3 locally?
For Llama 3 8B with 4-bit quantization, you need approximately 6-8GB VRAM/RAM, achievable on consumer GPUs like RTX 3060, RTX 4060, or even recent MacBooks with 16GB unified memory. Llama 3 70B with 4-bit quantization requires 35-40GB, necessitating professional GPUs like RTX 6000 Ada, A6000, A100 40GB, or multiple consumer GPUs. The 405B model needs 200GB+ even with aggressive quantization, practically requiring cloud deployment on multi-GPU instances. Most developers start local experimentation with 8B on personal hardware, then migrate to cloud infrastructure (AWS, Google Cloud, Azure) for larger models or production deployment. Cloud GPU instances cost $1-3 per hour for 70B-capable hardware, making occasional use affordable while avoiding $15,000-40,000 hardware purchases.
Q6: Does Llama 3 work offline without internet connection?
Yes, once you’ve downloaded model weights and installed necessary software, Llama 3 runs entirely offline without any internet connectivity. This makes it ideal for privacy-sensitive applications, air-gapped environments, remote locations with unreliable connectivity, or scenarios requiring guaranteed uptime independent of third-party services. The offline capability contrasts sharply with API-based models requiring constant internet access. However, initial setup requires downloading large model files (16GB for 8B, 140GB for 70B, 800GB for 405B), so plan for substantial one-time download requirements. After setup, the models function completely locally—no data leaves your device or infrastructure.
Q7: How do I ensure Llama 3 doesn’t generate inappropriate or harmful content?
Llama 3 instruct-tuned models include safety training that refuses many harmful requests, but no system is perfect. Implement multiple defensive layers: content filtering on inputs to block obviously problematic prompts before reaching the model, output moderation using specialized classification models to catch inappropriate generations, human review for high-stakes or public-facing applications, rate limiting to prevent systematic abuse attempts, and clear user guidelines explaining acceptable use. Additionally, fine-tuning on examples demonstrating your specific safety standards improves alignment with your requirements. For particularly sensitive applications (children’s products, healthcare, etc.), combine multiple safety measures and maintain conservative human oversight rather than relying solely on model-level safeguards. Remember that responsibility lies with deployers to implement appropriate safety measures for their specific use cases.